
OpenCOOD数据集
OpenCOOD数据集
OpenCOOD同时支持OPV2V(ICRA2022)和V2XSet(ECCV2022)数据集。
数据分割
OPV2V数据集可分为4个不同的文件夹:train、validation、test和test_culvercity
train:包含所有训练数据
validate:用于训练期间的验证
test:calrla默认城镇的测试集
test_culvercity:洛杉矶数字小镇Culver的测试集
场景数据
OPV2V总共有73个场景,其中每个场景都包含来自不同时间戳的不同agents的数据流。
Agents内容
在每个场景文件夹下,当前场景中出现的每个智能代理~(即连接的自动化车辆)的数据都保存在不同的文件夹中。

在每个智能体文件夹中,将保存不同时间戳的数据。这些时间戳由五位整数表示,作为文件名的前缀(例如00700.pcd)。agents文件夹中有三种类型的文件:激光雷达点云(.pcd文件)、相机图像(.png文件)和元数据(.yaml文件)。
激光雷达(LiDAR)
激光雷达数据保存在Open3d软件包中,名称中有一个后缀“.pcd”。
相机图片
每个CAV配备4个RGB摄像机(检查https://mobility-lab.seas.ucla.edu/opv2v/以查看这些相机的安装位置)来捕捉周围场景的360度视图。camera 0、camera 1、camera 2和camera 3分别表示前、右后、左后和后相机。
Data Annotation
所有元数据都保存在yaml文件中。它在当前时间戳中记录以下重要信息:
- 自我信息:在卡拉世界坐标下,当前的自我姿态(有GPS噪声和无GPS噪声)、以km/h为单位的自我速度、激光雷达姿态和未来规划轨迹。
- 校准:从每个相机到激光雷达传感器的本征矩阵和相机本征矩阵。
- 物体注释:周围每辆人类驾驶车辆的姿态和速度,该车辆至少有一个点被agetns的激光雷达传感器击中。有关更多详细信息,请参阅数据注释部分。
Data Collection Protocol
除了agents内容,每个场景数据库还有一个名为data_procol.yaml的yaml文件。这个yaml文件记录了模拟配置,以收集当前场景。它用于记录回放数据,并使用户能够在不更改原始事件的情况下为新任务添加/修改传感器。
为了帮助用户在CARLA中收集具有相似数据格式和结构的定制数据(例如,不同的传感器配置和模态),我们在OpenCDA的feature/data_collection分支中发布了我们的OPV2V数据收集代码。用户可以参考其文档以获取详细说明。
这个数据集有个相关的论文在arxiv.
相关工作
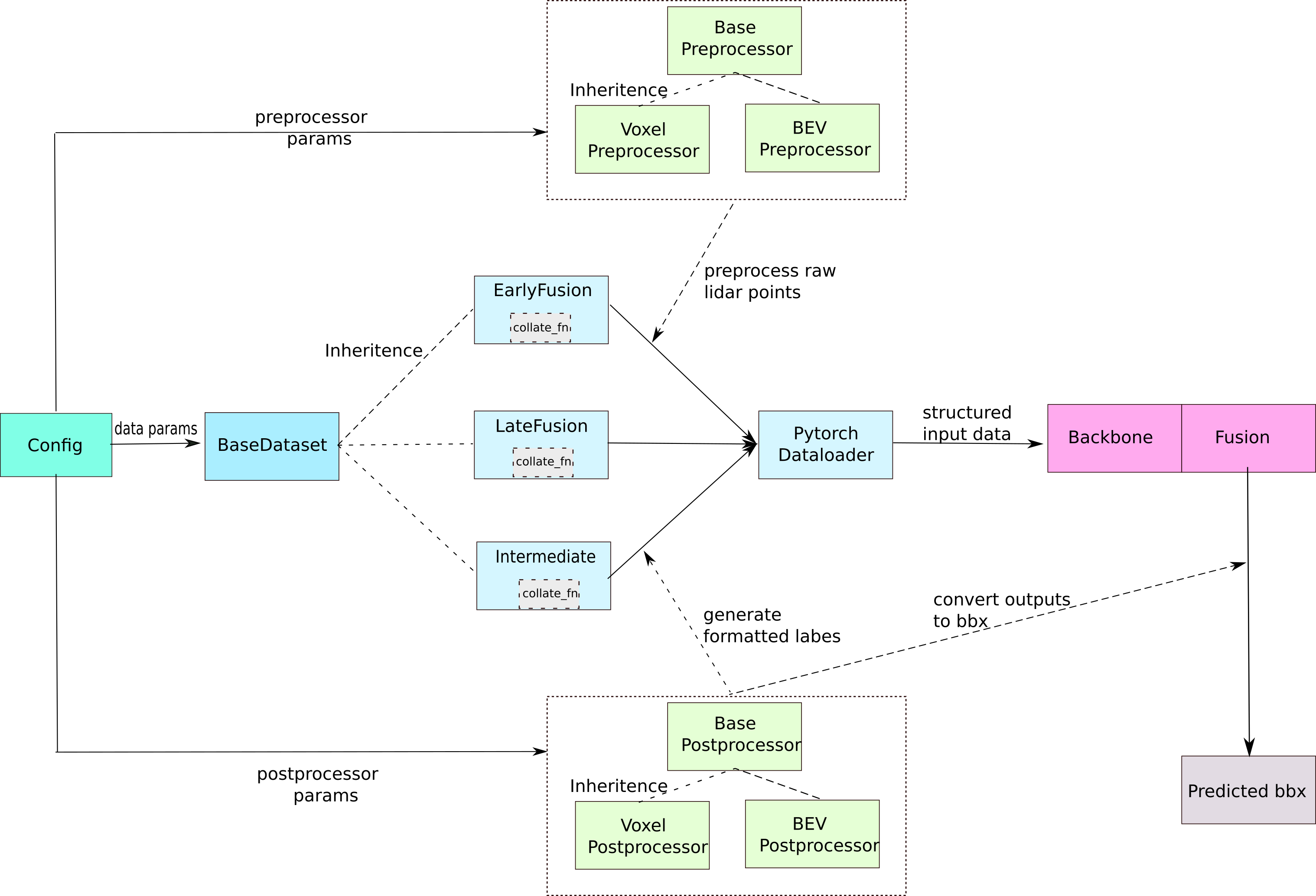
V2V 感知方法可分为三类:早期融合、晚期融合和中间融合.
早期融合: 早期的融合方法与通信范围内的 CAV 共享原始数据,ego车辆将根据汇总的数据预测对象这些方法保留了完整的传感器测量结果,但需要较大的带宽,难以实时操作
后期融合方法会传输输出,并将接收到的建议融合为一致的预测结果。 Rauch 等人提出了一种基于 Car2X 的感知模块,通过 EKF 在空间和时间上联合调整共享边界框提案。
利用基于机器学习的方法来融合不同连接agents生成的建议。优点是带宽低,缺点模型的性能在很大程度上取决于每个agents在车辆网络中的表现.
为了同时满足带宽和检测精度的要求,研究人员对中间融合进行了研究.
F-cooper利用最大集合来聚合共享的体素特征,V2VNet则根据共享信息联合推理边界框和轨迹。
本文工作
本文提出的Attentive Intermediate Fusion pipeline

由于来自不同联网车辆(CAV)的传感器观测数据可能会产生不同程度的噪声,一种既能关注重要观测结果,又能忽略干扰观测结果的方法对于稳健检测至关重要。
提出的Attentive Intermediate Fusion pipeline由 6 个模块组成:元数据共享、特征提取、压缩、特征共享、注意融合和预测。
Metadata Sharing and Feature Extraction
我们首先广播每个 CAV 的相对姿态和外部特征,以建立一个空间图,其中每个节点都是通信范围内的一个 CAV,每条边代表一对节点之间的通信通道。构建图形后,将在组内选择一辆自我车辆,而所有相邻的 CAV 都会将自己的点云投射到自我车辆的激光雷达框架上,并根据投射的点云提取特征。这里的特征提取器可以是现有 3D 物体检测器的基础。
Compression and Feature sharing
V2V通信中硬件对传输带宽有限制.传输原始的高维特征图通常需要很大的带宽,因此有必要进行压缩.
传输原始的高维特征图通常需要很大的带宽,因此有必要进行压缩。
使用encoder-decoder架构,将特征进行压缩
编码器由一系列二维卷积和最大池化组成,bottleneck(其实就是latent variable,潜变量这种东西)处的特征图将广播给ego车。
ego车辆侧包含多个解卷积层的解码器将恢复压缩信息,并将其发送给注意力融合模块。
Attentive Fusion
使用了self-attention融合特征,同一特征图中的每个特征向量都与原始点云中的某些空间区域相对应。
简单地平铺特征图并计算特征的加权和将会打破空间相关性。
取而代之的是,我们为特征图中的每个特征向量构建一个局部图,其中的边是为来自不同连接车辆的相同空间位置的特征向量构建的。
Prediction Header
融合后的特征将输入预测头生成边界框建议和相关的置信度分数.
我们在数据集上实施了四种SOTA的基于激光雷达的 3D 物体检测器,并将这些检测器与三种不同的融合策略进行了整合
BenchMark测试
在数据集上实施了四种最先进的基于激光雷达的 3D 物体检测器,并将这些检测器与三种不同的融合策略进行了整合
选定的 3D 物体检测器:我们选择 SECOND 、VoxelNet 、PIXOR 和 PointPillar作为三维激光雷达检测器进行基准分析。

早期融合
所有激光雷达点云都将根据 CAV 之间共享的姿态信息投射到小我车辆的坐标框架中,然后ego车辆将汇总所有接收到的点云,并将其反馈给探测器。
后期融合
每个 CAV 将独立预测具有置信度分数的边界框,并将这些输出广播给ego车。之后,将对这些建议进行非最大抑制(NMS),以生成最终的物体预测结果。
中期融合
为了评估所提出的流水线,我们只需要在现有的网络架构中添加压缩、共享和关注(CSA)模块。由于 4 个不同的检测器添加 CSA 模块的方式类似,在此仅展示 PIXOR 模型的中间融合架构

评价指标
在测试和验证集的每个场景中,我们从所有生成的 CAV 中选择一辆固定车辆作为自我车辆。
采用 0.5 和 0.7 IoU临界值的平均精度(AP)来评估不同的模型
结果
